
在当今的电商时代,订单处理的可靠性直接决定了用户体验和业务成败。传统的单体架构难以应对流量洪峰,而微服务架构又带来了复杂的运维挑战。无服务器架构(Serverless) 结合 工作流编排 为我们提供了一种优雅的解决方案。
本文将深入解析一个基于 AWS Step Functions 的完整订单处理系统架构,展示如何利用无服务器服务构建弹性伸缩、容错性强、可观测的业务流程。
架构全景图
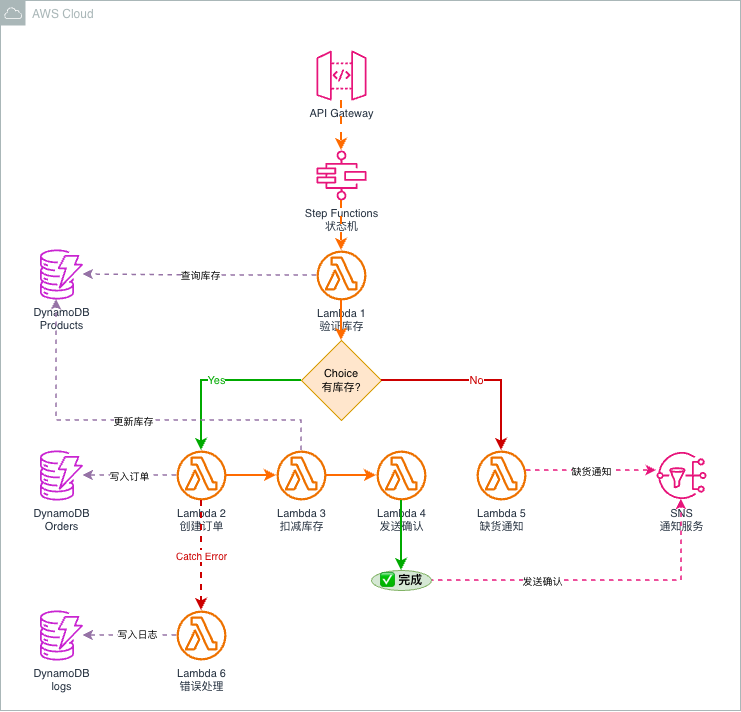
这个架构图展示了一个经典的电商订单处理流程,核心组件包括:
核心流程拆解
第一阶段:库存验证(Lambda 1)
# 伪代码示例:库存验证逻辑
def lambda_handler(event, context):
product_id = event['product_id']
quantity = event['quantity']
# 查询 DynamoDB Products 表
stock = dynamodb.get_item(
TableName='Products',
Key={'product_id': product_id}
)
available = stock['Item']['inventory'] >= quantity
return {
'product_id': product_id,
'requested_quantity': quantity,
'available_quantity': stock['Item']['inventory'],
'in_stock': available # 此字段驱动 Choice 状态
}关键设计点:
使用 DynamoDB 强一致性读取 确保库存数据准确
返回结构化数据供 Step Functions Choice 状态进行分支判断
第二阶段:条件分支(Choice State)
Step Functions 的 Choice 状态实现了业务规则的可视化编排:
有库存?
├── Yes → 执行订单创建流程(绿色路径)
└── No → 执行缺货通知流程(红色路径)这种声明式的工作流定义,比代码中的 if-else 更易维护和审计。
第三阶段A:正常订单流程(Happy Path)
Lambda 2: 创建订单
在
DynamoDB Orders表中写入订单记录状态设为
PENDING生成唯一订单 ID
Lambda 3: 扣减库存
使用 DynamoDB 事务写入 原子性更新库存
关键:先创建订单再扣库存,避免超卖
Lambda 4: 发送确认
调用 SNS 发送订单确认通知
异步解耦,不阻塞主流程
完成状态
订单状态更新为
CONFIRMED
第三阶段B:缺货处理流程(Alternative Path)
Lambda 5: 缺货通知
立即通知用户商品暂时缺货
可触发补货流程或推荐替代商品
第四阶段:错误处理与可观测性
Lambda 6: 错误处理
捕获 Lambda 2 的异常(如数据库写入失败)
记录详细错误上下文到
DynamoDB Logs表支持 死信队列(DLQ) 和自动重试策略
关键设计模式:
Saga 模式:Lambda 2-3-4 构成一个分布式事务,失败时通过补偿操作保证最终一致性
断路器模式:连续失败时触发熔断,保护下游服务
技术亮点分析
1. 事件驱动架构的优势
API Gateway → Step Functions → Lambda → DynamoDB/SNS自动扩缩容:从 0 到数千并发无需配置
按调用付费:闲时零成本,忙时线性扩展
松耦合:各组件通过事件总线通信,独立演进
2. Step Functions 的编排能力
相比纯 Lambda 链式调用,状态机提供了:
可视化监控:AWS 控制台实时查看流程执行状态
内置重试:任务失败自动指数退避重试
长时间运行:标准工作流可运行长达 1 年
人工审批:支持
Wait for Callback模式插入人工步骤
3. DynamoDB 单表设计
三个表的职责分离体现了 CQRS(命令查询职责分离) 思想:
生产环境建议
性能优化
Lambda 并发预留:为关键路径(Lambda 2-3)配置 Provisioned Concurrency,消除冷启动
DynamoDB DAX:对 Products 表启用缓存,降低读取延迟
Step Functions Express Workflow:若订单流程 < 5 分钟,使用 Express 模式降低成本 95%
安全加固
# 最小权限 IAM 策略示例
Lambda1Role:
Permissions:
- Effect: Allow
Action:
- dynamodb:GetItem
Resource: !GetAtt ProductsTable.Arn
Condition:
ForAllValues:StringEquals:
dynamodb:LeadingKeys: ["${aws:PrincipalTag/ProductAccess}"]可观测性
X-Ray 追踪:端到端查看请求在各服务间的流转
CloudWatch Logs Insights:分析错误日志模式
自定义指标:在 Lambda 中埋点,监控库存扣减成功率
总结
这个架构展示了无服务器优先(Serverless First)的设计哲学:
"将业务逻辑交给 Lambda,将流程编排交给 Step Functions,将状态管理交给 DynamoDB,让团队专注于业务价值而非基础设施。"
适用场景:
✅ 电商订单、支付流程
✅ 物联网设备数据处理
✅ 多媒体转码工作流
✅ 任何需要可靠执行、可视化监控的多步骤业务流程
希望这篇解析对你构建无服务器应用有所启发。如果你正在设计类似的系统,欢迎在评论区交流架构决策的权衡与思考。


